
For even a casual observer of Donald Trump's electoral career, it is clear that the former, and future, president has centered his political project on an opposition to immigration. He has, over and over again, made inflammatory statements about immigrants — many of which collapse under scrutiny.
In an election year in which immigration was a critical issue for voters and popular anti-immigrant sentiment grew, our question became: How can we understand Trump's immigration rhetoric in its full scope and importance, and how might we similarly interrogate Vice President Kamala Harris’ language?
The Marshall Project set out to tackle this question ahead of the 2024 election. Focusing on immigration — an area of public discourse rife with falsehoods, and an explicit cornerstone of Trump’s campaign — we decided to take a bird’s-eye view of each candidate’s comments on immigration over decades of public life available in Factba.se, a public database of presidential candidate statements.
Our goal was to process hundreds of thousands of lines of transcript text to pull out 1) how many of these statements were about immigration, 2) how many of those immigration statements were repetitions of the same idea and 3) how many of those repeated ideas were false.
Processing large amounts of information is an important challenge in journalism. Until recently, a processing task of this scale would have been abandoned as impossible: No reporter can realistically read and categorize 10 million words — we roughly estimated it would take the average reader around 700 hours. Enter natural language processing.
NLP is the use of computers to understand, process and generate text. Techniques like topic modeling, classification and clustering are long-established in computer science, and have recently become more accessible in less technical fields through increasing computational resources and improved interfaces. These methods can vastly increase reporters’ capacity to find and process the information they are looking for.
We used NLP techniques to evaluate the scale and nature of Trump’s and Harris’ immigration rhetoric, which were starkly different due to their approaches to immigration and the differing lengths of their candidacies. After scraping over 350,000 lines of text from almost 4,000 Factba.se transcripts dating from 1976 to the end of September 2024, we filtered and grouped the statements into those made by each of the candidates, and used a binary classifier to identify over 12,000 of them that were about immigration.
From there, we used a clustering algorithm to create groups of similar claims. Reporters manually reviewed the results, combining some clusters and splitting up others, refining them into a final set of major claims about immigration. We tailored a binary classifier for each one and ran it on the entire corpus, which gave us, for each claim, a set of statements likely to be making that claim. Finally, reporters manually reviewed each set of statements, confirming which ones were examples of that particular claim.
The result was a set of 13 claims carefully checked by reporters, and a lower bound for the number of times Trump has made some variation of each one. That allowed us to show he has repeated some of the claims at least 500 times.
For example, Trump has referred to unauthorized immigrants as criminals at least 575 times, as snakes that bite at least 35 times, as coming from prisons, jails and mental institutions at least 560 times and as causing crime in sanctuary cities at least 185 times. He has described the construction of a wall on America’s southern border as essential to public safety at least 675 times, and has argued at least 50 times that mass deportations are acceptable because President Dwight Eisenhower did it. We found all of these claims to be either entirely false or, at the very least, highly misleading.
In this project, we used basic, trusted NLP methods to pull meaningful findings out of a mountain of text. And you can do it, too. By arming yourselves with NLP techniques to simplify large datasets into subsets that are more manageable for human review and using them to set lower bounds (such as “at least 50 times”), reporters like you can become more efficient without sacrificing accuracy.
We collaborated with Robert Flagg, a data scientist and father of Anna Flagg, one of the project’s reporters. He designed and developed code for the analysis with The Marshall Project, and provided expert guidance on NLP to reporters.
Here are some more details about how we did it:
Scraping
We needed the raw data, so our first step was to scrape speech transcripts for the candidates from Factba.se. We obtained permission from Factba.se before scraping.
Using Python and the Beautiful Soup and Selenium libraries, we pulled down a list of both candidates’ speeches, interviews and other available transcripts from the Factba.se search results page, including the URLs of individual transcripts, which we also then scraped. Factba.se provides the transcripts conveniently broken up into small segments of text, usually one or two sentences, labeled by speaker. We counted each of those snippets of speech as one statement.
After scraping, the result was a dataset of public statements of the candidates, interviewers and other participants in the speaking events, as well as the date, location and other pieces of metadata about the event.
Extracting statements about immigration
Next, we needed to pull out all the statements related to immigration. We decided to use a binary classification model, a method of categorizing data into one of two groups, because the nature of our problem was to label each statement as one of two things: about immigration, or not about immigration.
Such a classifier works by learning patterns from an initial “training set” of labeled data, which it can then apply to labeling new data. So we needed some labeled data — and a significant amount of it. But we didn’t want to spend weeks having humans label sample material. Instead, we ran a subset of the data through the large language models (LLMs) GPT-4o mini and Claude 3.5 Haiku, which we prompted to label each statement as either about immigration or not.
To improve the accuracy of the LLM responses, we used Clue and Reasoning Prompting, a method that requires the LLM to reason step-by-step by first generating a list of helpful hints, and then articulating a diagnostic reasoning process before making a judgment about whether the passage is or is not about immigration.
Using the resulting labeled data as an initial training set, we fine-tuned a RoBERTa binary classifier, a state-of-the-art classification model. We ran the model on the overall unlabeled data. When the model expressed low confidence in its answer, reporters manually reviewed and provided labels, added the resulting labeled data to the training set and trained the model again. We repeated this cycle several times to improve the model’s performance, a technique known as active learning.
Clustering to identify major themes in immigration rhetoric
We hypothesized that many of the statements were repetitions of the same idea. So we needed a way to group together statements that were similar in meaning.
We turned to a common deep-learning tool known as a transformer, which works by representing input data as high-dimensional vectors. Transformers were introduced in “Attention Is All You Need,” a seminal paper by Google developers that became a key building block in the field. Here are some more details about transformers.
In our case, our input data was the statements. We used a sentence transformer to embed the statements in high dimensions, and the UMAP dimension reduction technique to create a simplified representation of each statement. We then clustered those into groups of related statements using DBSCAN.
Human review
The goal of this analysis was to explore the universe of candidate statements about immigration, and report out the major themes we saw and how often they were repeated. Our findings needed to be 100% reported by humans. All our language processing was to get to the stage where reporters could step in with their expertise.
Reporters read statements from each cluster that had been highlighted. To aid this review, we again used an LLM, prompting it for a summary of each cluster based on its 10 most relevant statements as defined by the model’s reported level of confidence. We paired this information with WizMap, a tool used to visualize high-dimensional embeddings, which reporters used to see and explore the immigration statements.
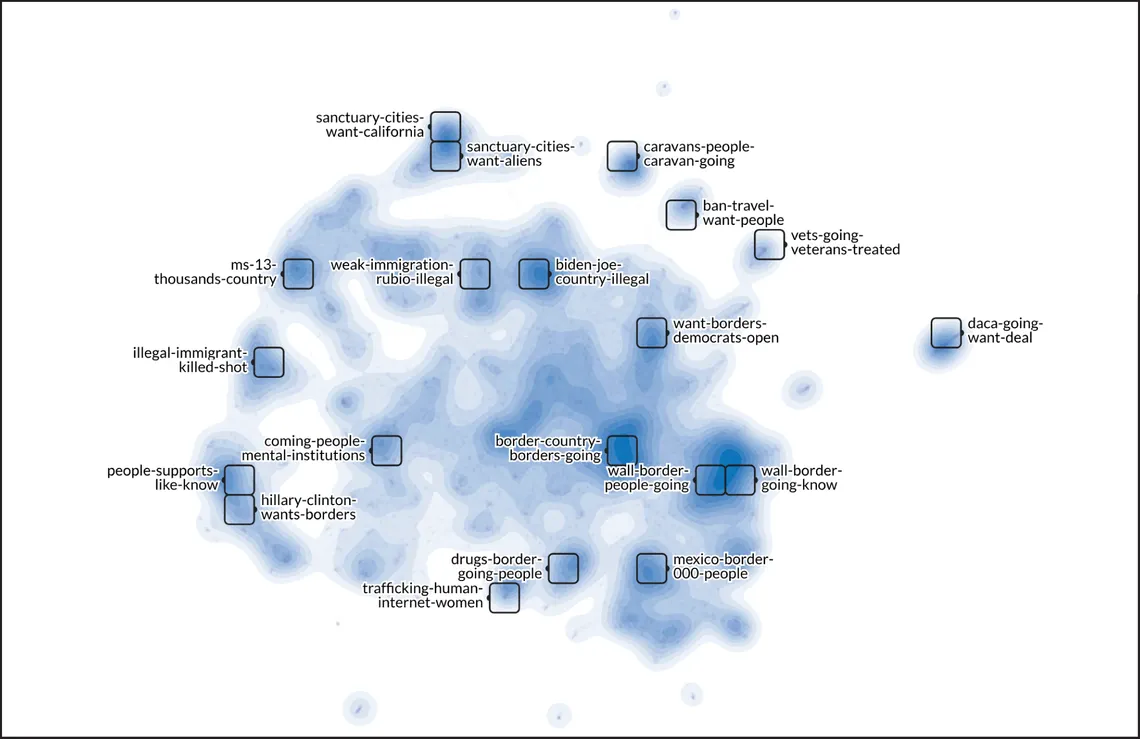
Reporters combined some clusters and split apart others. The computer-aided work made this process much more efficient, quickly surfacing themes and patterns from an otherwise overwhelming amount of text.
Counting statements for each claim
Our final set of immigration claims in hand, we again trained the binary classifiers, looking for statements that matched each claim. We used a similar process to before, fine-tuning each classifier with a set of statements labeled by an LLM and improved by human review.
Reporters then manually reviewed the statements returned by the classifier, sometimes amounting to hundreds of statements or more for a single claim. Any statement deemed not to strictly match the claim was thrown out. These false positives were more frequent for some claims than others, sometimes numbering in the hundreds.
The result was a comprehensive list of major repeated claims about immigration driven by the candidates’ catalogs of immigration-related statements. For each of the Trump claims that we fact-checked, we had a set of up to hundreds of instances, all confirmed by human reporters.
For example, the model surfaced a pattern in Trump’s speeches of citing a group of isolated, tragic cases to allege that undocumented immigrants are killing Americans en masse. Reporters read all the statements classified in that category, throwing out any false positives, and found that Trump had made this claim more than 235 times.
Reporting with natural language processing
In this project we used classifiers, LLMs and clustering to narrow a large dataset of text, using human reporters at strategic points to guide the process, at the end producing an entirely human-reported set of results.
We hope this work can be a useful reference for how reporting projects can use computers for something they are good at — processing lots of text — and humans for something they are good at — providing nuanced editorial judgment.
Right now, reporters have a great opportunity to use trusted NLP methods as a powerful tool to both expand and speed up their work. By mixing computer-aided techniques with traditional journalism, we are in a better position than ever before to tackle reporting problems that involve vast amounts of information, without sacrificing accuracy.